Z_Image_Turbo文生图
- 笔记
- 2026-04-20
- 205热度
- 0评论
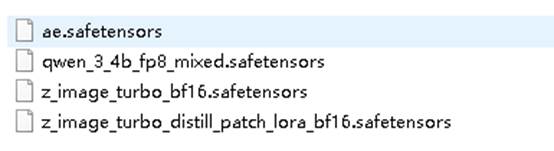
一、ae.safetensors模型
VAE(变分自编码器,Variational Autoencoder)在大模型中的核心价值 = 高效压缩 + 连续潜在空间 + 高质量生成 + 细节优化。它不仅是生成式模型的“基础设施”,也是平衡计算效率与输出质量的关键组件。
存放目录为:安装目录ComfyUI\models\Vae
二、qwen_3_4b_fp8_mixed.safetensors
千问模型3模型,负责将自然语言文本转换为机器能识别的语义向量,供后续图像生成模型使用。
存放目录为:安装目录ComfyUI\models\\text_encoders
三、z_image_turbo_bf16.safetensors
图像生成模型
存放目录为:安装目录ComfyUI\models\diffusion_models
四、z_image_turbo_distill_patch_lora_bf16.safetensors
z_image_turbo lora模型,在大模型中,LoRA(Low-Rank Adaptation,低秩自适应)模型的核心作用是实现高效、低成本的微调,同时保留原始模型的通用能力,并支持灵活的任务切换。
存放目录为:安装目录ComfyUI\models\loras
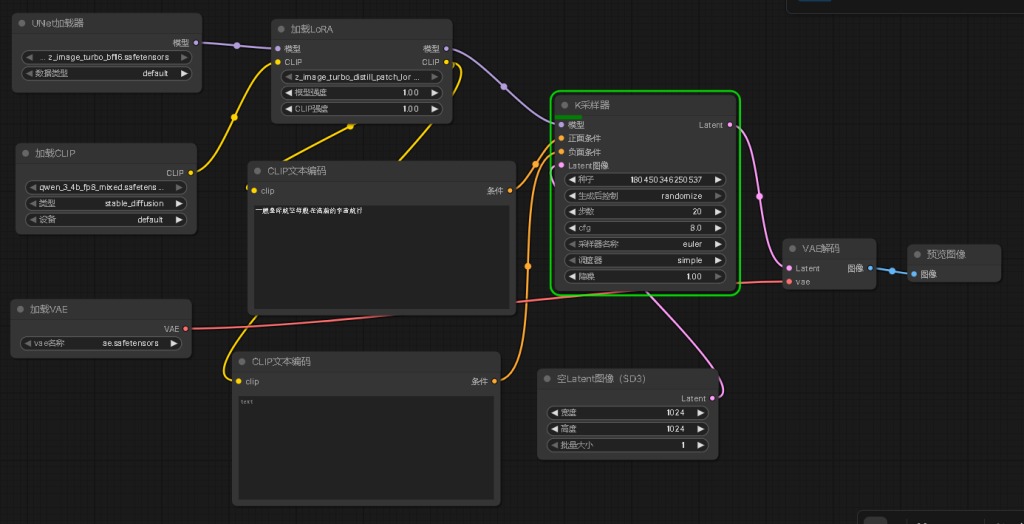
五、插入节点
1. UNeT加载器:加载文生图模型z_image_turbo_bf16.safetensors
2. 加载Clip:加载千问3模型qwen_3_4b_fp8_mixed.safetensors
3. 加载Vae:加载Vae模型ae.safetensors
4.加载Lora:加载lora模型:z_image_turbo_distill_patch_lora_bf16.safetensors
5. Clip文本编辑器:输入文生图文本,分为正面条件和负面条件,分别表示想要的和不想要的
6. K采样器:执行扩散模型逆向去噪过程的核心组件,其主要作用是将随机噪声逐步转化为符合文本提示的清晰图像。
7. 空Latent图像:图像大小控制
8. VAE解码:负责将抽象的潜在表示转化为高质量、可解释的最终输出。
9. 预览图像:将生成的图像预览显示。